Часто бывает, что на системе Linux произошла незапланированная или по неизвестным очевидным причинам, перезагрузка. Поиск и устранение первопричины может помочь предотвратить повторение таких проблем и избежать незапланированных простоев.
Есть несколько способов выяснить, что вызвало перезагрузку. В этой статье рассмотрим способы использования доступных утилит и журналов в системе Linux для устранения таких сценариев.
Проверка времени перезагрузки
Чтобы посмотреть, когда именно произошла перезагрузка системы можно воспользоваться командами who -b и last -x | head | tac
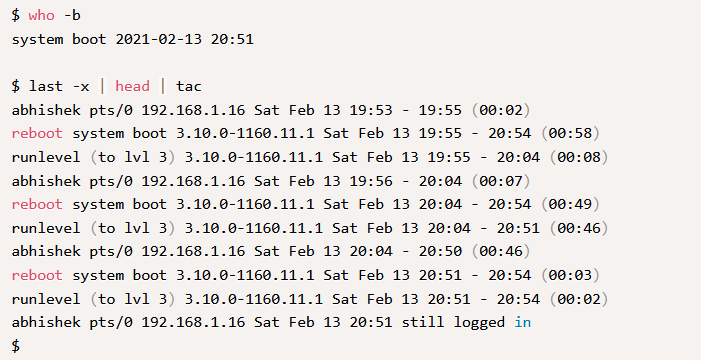
Проверка системных журналов
Кроме того, можно сопоставить время перезагрузки, которую требуется диагностировать, с системными сообщениями.
Для систем CentOS/RHEL журналы можно найти по адресу /var/log/messages, а для систем Ubuntu/Debian — по адресу /var/log/syslog. Для фильтрации или поиска конкретных данных можно использовать команду tail или cat, grep.
Как видно из приведенных ниже журналов, такие записи предполагают завершение работы или перезагрузку, инициированную администратором или пользователем root. Эти сообщения могут варьироваться в зависимости от типа ОС и способа запуска перезагрузки или завершения работы, но вы всегда найдете полезную информацию, просматривая системные журналы, хотя этого не всегда может быть достаточно, чтобы определить причину.
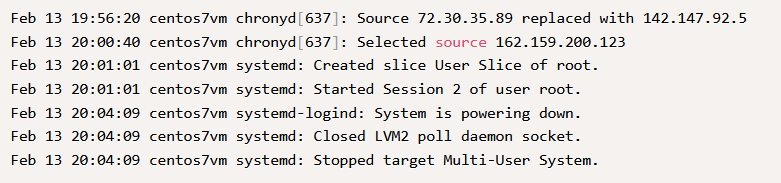
Ниже приведена одна такая команда, которую можно использовать для фильтрации системных журналов:
sudo grep -iv ': starting|kernel: .*: Power Button|watching system buttons|Stopped Cleaning Up|Started Crash recovery kernel'
/var/log/messages /var/log/syslog /var/log/apcupsd*
| grep -iw 'recover[a-z]*|power[a-z]*|shut[a-z ]*down|rsyslogd|ups' Зафиксированные события не всегда могут быть конкретными. Всегда отслеживайте события, которые дают признаки предупреждений или ошибок, которые могут привести к выключению или сбою системы.
Проверка журнала auditd
Для систем, использующих auditd – это отличное место для проверки различных событий с помощью инструмента ausearch. Используйте приведенную ниже команду для проверки последних двух записей из журналов аудита. Установка на CentOS: sudo yum install audit. Установка на Debian: sudo apt-get install auditd
$ sudo ausearch -i -m system_boot,system_shutdown | tail -4Появится сообщение о двух последних остановках или перезагрузках. Если это сообщает о SYSTEM_SHUTDOWN, за которым следует SYSTEM_BOOT, все должно быть хорошо. Но, если он сообщает две строки SYSTEM_BOOT подряд или только одно сообщение SYSTEM_BOOT, то, скорее всего, система некорректно завершила работу. Вывод при нормальной работе должен быть примерно следующим:
$ sudo ausearch -i -m system_boot,system_shutdown | tail -4
----
type=SYSTEM_SHUTDOWN msg=audit(Saturday 13 February 2021 A.852:8) : pid=621 uid=root auid=unset ses=unset subj=system_u:system_r:init_t:s0 msg=' comm=systemd-update-utmp exe=/usr/lib/systemd/systemd-update-utmp hostname=? addr=? terminal=? res=success'
----
type=SYSTEM_BOOT msg=audit(Saturday 13 February 2021 A.368:8) : pid=622 uid=root auid=unset ses=unset subj=system_u:system_r:init_t:s0 msg=' comm=systemd-update-utmp exe=/usr/lib/systemd/systemd-update-utmp hostname=? addr=? terminal=? res=success' В приведенных ниже выходных данных перечислены два последовательных сообщения SYSTEM_BOOT, которые могут указывать на аварийное завершение работы, хотя результаты нужно скорректировать с данными системного журнала.
$ sudo ausearch -i -m system_boot,system_shutdown | tail -4
----
type=SYSTEM_BOOT msg=audit(Saturday 13 February 2021 A.852:8) : pid=621 uid=root auid=unset ses=unset subj=system_u:system_r:init_t:s0 msg=' comm=systemd-update-utmp exe=/usr/lib/systemd/systemd-update-utmp hostname=? addr=? terminal=? res=success'
----
type=SYSTEM_BOOT msg=audit(Saturday 13 February 2021 A.368:8) : pid=622 uid=root auid=unset ses=unset subj=system_u:system_r:init_t:s0 msg=' comm=systemd-update-utmp exe=/usr/lib/systemd/systemd-update-utmp hostname=? addr=? terminal=? res=success' Анализ журнала systemd
Чтобы сохранить журнал системных логов на диске, необходимо иметь постоянный системный журнал, иначе логи будут очищаться при перезагрузке. Для этого можно либо внести изменения в /etc/systemd/journald.conf, либо создать каталог самостоятельно с помощью следующих команд:
$ sudo mkdir /var/log/journal
$ sudo systemd-tmpfiles --create --prefix /var/log/journal 2>/dev/null
$ sudo systemctl -s SIGUSR1 kill systemd-journald После этого можно дополнительно перезагрузить систему для ввода нескольких записей перезагрузки в журнал, хотя это и не требуется.
Приведенную ниже команда позволяет выводить список записанных событий о загрузке из журнала:
$ journalctl --list-bootsПример выходных данных:
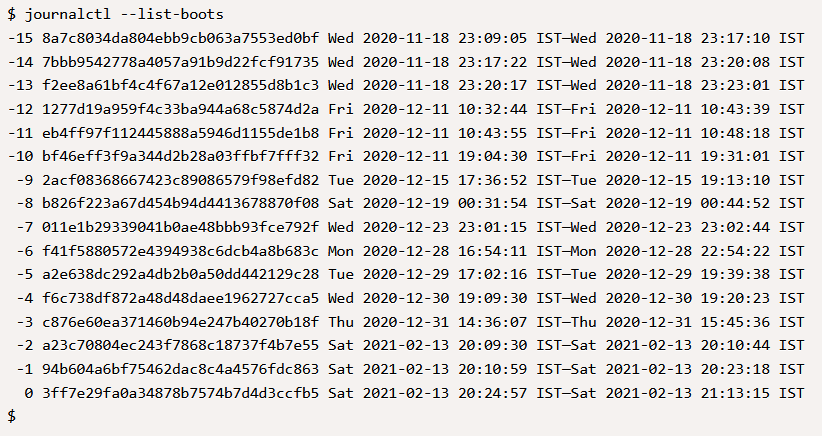
Как видно на рисунке, в системе есть несколько событий загрузки. Для дальнейшего анализа причины конкретной перезагрузки используйте:
$ journalctl -b {num} –nЗдесь {num} будет индексом, заданным в команде journalctl --list-boots в первом столбце.
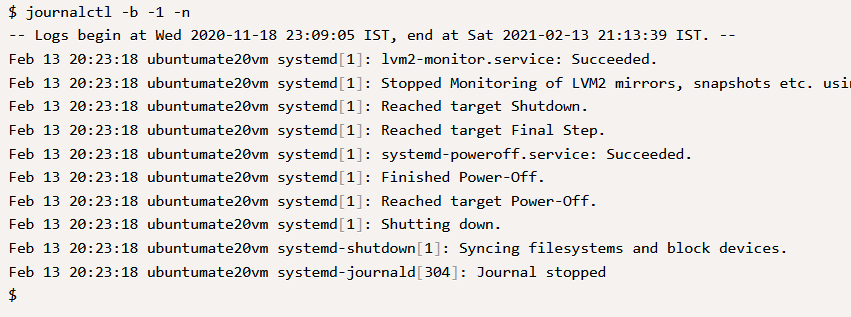
В приведенных выше выходных данных можно просмотреть сообщения, зарегистрированные в журнале, и отследить аномалии, если таковые имеются.
Заключение
Приведенные выше примеры дают вам возможность начать поиск и устранение неисправностей. Используя комбинацию таких инструментов и журналов, вы можете быть уверены в том, что произошло и как перезагрузилась ваша система.
Проверьте системные журналы на наличие сообщений об ошибках или других подсказок, которые могут указывать на причину перезагрузки во время перезагрузки. Доступ к системным журналам можно получить через каталог /var/log. Некоторые общие файлы журналов для проверки включают messages, syslog, dmesg, and kern.log.
Вот 3 причины, которые могут вызвать перезагрузку сервера:
1. Проверьте, не произошло ли на сервере отключение питания или другой аппаратный сбой, который мог вызвать перезагрузку. Это можно сделать, проверив системные журналы на наличие сообщений, связанных с отключением питания или аппаратными проблемами, или проверив аппаратное обеспечение сервера на наличие видимых признаков повреждения.
2. Проверьте, не был ли сервер перезагружен из-за kernel panic или другой системной ошибки. Это можно сделать, проверив системные журналы на наличие сообщений, связанных с Kernel panic или другими ошибками. Kernel panic — это состояние, которое возникает, когда ядро Linux не может нормально функционировать из-за серьезной ошибки или сбоя. Когда происходит kernel panic, ядро останавливает выполнение и отображает сообщение об ошибке, известное как «panic code».
Вот несколько примеров кодов паники ядра, которые могут отображаться в Linux:
- «BUG: unable to handle kernel NULL pointer dereference» — это сообщение об ошибке указывает на то, что ядро обнаружило нулевой указатель и не может продолжить выполнение.
- «BUG: bad page state in process» — это сообщение об ошибке указывает на то, что ядро обнаружило проблему с управлением памятью процесса.
- «BUG: soft lockup — CPU# stuck for xs!» — Это сообщение об ошибке указывает на то, что ядро обнаружило, что ЦП застрял в цикле в течение длительного периода времени. проверьте этот пост, чтобы получить информацию об этой ошибке.
- «BUG: unable to handle kernel paging request» — это сообщение об ошибке указывает на то, что ядро столкнулось с проблемой подкачки, которая представляет собой процесс передачи данных между основной памятью и вторичной памятью.
- «BUG: scheduling while atomic» — это сообщение об ошибке указывает на то, что ядро столкнулось с проблемой планирования, то есть процесса выделения процессорного времени процессам.
3. Проверьте, не был ли сервер перезагружен из-за проблемы с программным обеспечением, например из-за ошибки в приложении или системном компоненте. Если причину неожиданной перезагрузки определить невозможно, может потребоваться сбор дополнительной информации путем сбора системных журналов и других диагностических данных.